Now it comes time to put what we have learnt into a single Python script. We will need to paste the root file path into the code, and call out the name and location of the result csv path. In the final version these two pieces of data will change. The root folder will be found using a user interface. In fact I think that should be the second prototype.
Discussion
The code is going to the bottom of this page, as it is necessarily quite long. And we have walked through the different parts. Some of what ChatGPT was good, some I don’t like.
The function ChatGPT gave me where the csv is written is called traverse_and_hash which is a code smell. Method or function names with the word ‘and’ in the name violate the Single Responsibility Principle. Fashions come and go in software development but I have never heard anyone trying to argue against SOLID.
Sorry ChatGPT, if you want to write code that you can manage in the future, you need to do better than this. You are not fired, but no pay rise for you this year.
Modules and Scripts
if __name__ == "__main__":
This lovely little line will allow me to port the script into the next prototype with no changes at all. If the code in the line above is in the file that is being run, then everything below it will be executed.
However if this file is being imported into another script anything below this line will not be run. So it allows you to set local variables for prototypes and testing, without having to remember to remove them in the final application.
Thank you to freecodecamp who explain it better than I do.
The Final Code
import os
import hashlib
import csv
def compute_md5(file_path):
md5_hash = hashlib.md5()
with open(file_path, "rb") as f:
for chunk in iter(lambda: f.read(4096), b""):
md5_hash.update(chunk)
return md5_hash.hexdigest()
def walk_through_files(path, extensions):
for (dirpath, dirnames, filenames) in os.walk(path):
for filename in filenames:
if filename.lower().endswith(extensions):
yield (filename, os.path.join(dirpath, filename))
def create_csv(csv_filepath):
with open(csv_filepath, 'w', newline='') as csvfile:
fieldnames = ['name', 'path', 'hash']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
csvfile.close()
def write_to_csv(csv_filepath, csv_data):
with open(csv_filepath, 'a', newline='') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=csv_data.keys())
writer.writerow(csv_data)
csvfile.close()
def analyse_files(root_directory, extensions, csvfile):
create_csv(csvfile)
for fname, filepath in walk_through_files(root_directory, extensions):
csv_data = {'File Name': fname, 'File Path' : filepath, 'MD5 Hash' : compute_md5(filepath)}
write_to_csv(csvfile, csv_data)
if __name__ == "__main__":
root_directory = "C:\\Users\\*****\\Desktop\\Team Turkey Run 2019"
extensions = (".jpg", ".jpeg")
csv_filename = "C:\\Users\\*****\\Desktop\\Team Turkey Run 2019\\TestOutput.csv"
analyse_files(root_directory, extensions, csv_filename)
The Outcome
Functional but excruciatingly slow.
- There should not be all those file opens,
- csv is definitely not the answer.
I think I need to prioritise this database.
Success
Despite being so slow, I managed to collect almost 40,000 entries in my cvs file.
- Saved as a proper spreadsheet.
- Sorted by Column C – the column with the hashes.
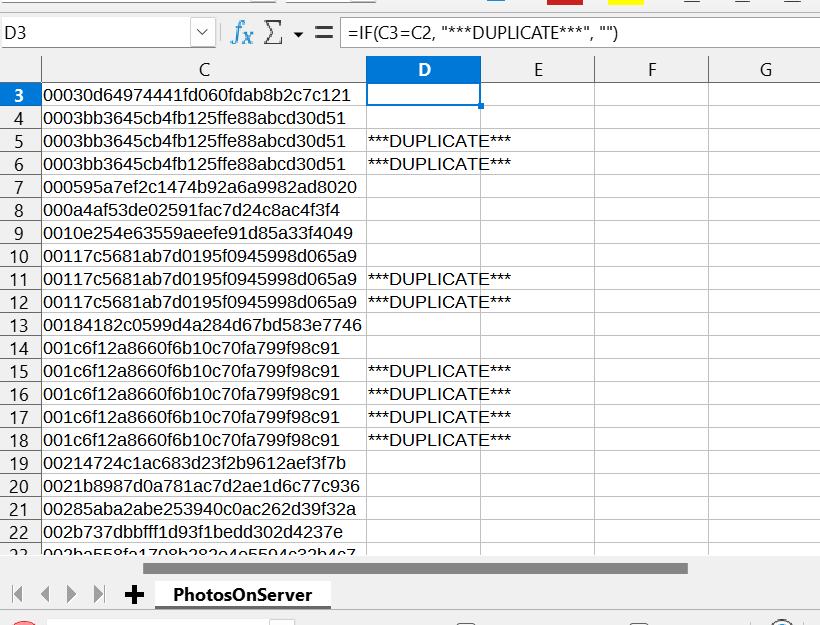
- Added the following formula to cell D3:
=IF(C3=C2, "***DUPLICATE***", "")- Copied this formulae down the rest of column D, as far as the data went.
So now I am able to locate duplicate files on the server, and I can go through, review and delete as required.
Phase 1 of this project is successfully completed.
What’s up, for all time i used to check blog posts here in the early hours in the morning, since i love to
gain knowledge of more and more.
Hi, i feel that i saw you visited my blog so i got here to return the desire?.I’m attempting to find issues to improve my web site!I
guess its adequate to make use of some of your concepts!!
Really helpful and very well explained. Thanks for
making complex topics simple.