I decided to get the md5 hash of a file. This is pretty much unique. It ignores dates or file sizes which may vary depending on different systems. But it will identify a file as different if it has been resized. There may be a reason to keep different sizes of files – if you write a website you should know that very well. But technically these are not duplicates. I would not like to accidentally discard a high-res photo and keep the low-res one.
The Environment
For setup I needed to:
- Install Visual Studio Code – jokes, I can’t survive long without it.
- Install Python. Yes I am on Windows so it does not come ready installed. Just head across to python.org
- Make a git repo and push it up to github. Yes I have a git repo, if you care enough you won’t have to try hard to find it.
- Boot up ChatGPT – hey ChatGPT understands Python better than me. I don’t have to go re-inventing wheels.
Compute MD5
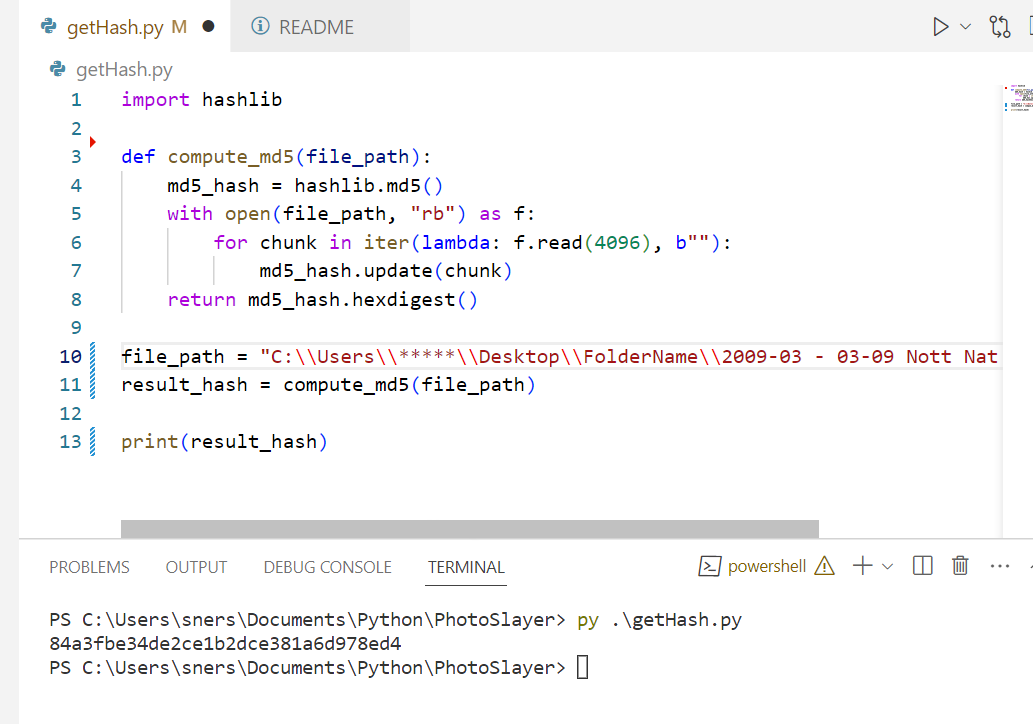
ChatGPT gave me this code:
import hashlib
def compute_md5(file_path):
md5_hash = hashlib.md5()
with open(file_path, "rb") as f:
for chunk in iter(lambda: f.read(4096), b""):
md5_hash.update(chunk)
return md5_hash.hexdigest()
Code Walkthrough
- Hashlib is a module where the magic happens.
- def means ‘define’, and here we are defining a function.
- The python ‘open’ command syntax is
open(file, mode). - “rb” stands for “read binary”. Thanks w3schools.
- The lambda is f.read(4096)
- The iteration is a way to process blocks of input from a file – example in the Python documentation.
- md5 hash is described on Stack Overflow.
Is Md5 Unique?
Well no, but it is pretty much unique, and in this use case it is more than enough.
In the unlikely event that we get two different files coming to the same code – well the user should be checking them anyway.